The 8 Ranking Criteria
On this page
Ranking criteria# A
These eight ranking criteria of Algolia’s tie-breaking algorithm help define what’s both textually and business relevant.
Typo#
Algolia can retrieve the records searched by the user even if a typing mistake was made. By default, words with 0, 1, or 2 typos per word will match. This is called typo-tolerance.
The Typo criterion in the ranking formula makes sure that records that match a query without typos (in other words, an exact match) ranks higher than ones that match with one typo, themselves ranking higher than ones that match with two typos.
Geo (if applicable)#
If you’re using the geo-search feature, results will be ranked by distance, from the closest to the farthest.
The precision of this ranking is set by the parameter aroundPrecision. For example, with aroundPrecision=100, two results up to 100 meters apart will be considered equal.
Words (if applicable)#
This criterion is only applicable if you are using the optionalWords setting.
By default, Algolia discards all results that don’t contain all the words of the query. But with optionalWords, where you declare some words as optional, the Words criterion will rank them by the number of words typed by the user that matched. Keep in mind that this isn’t a count of the number of times the word appears in the record, but rather a count of the number of words typed by the user that matched.
For example, if the user typed two words, the maximum score for this criterion is 2 - even if a record contains this word 10 times.
Filters#
If a query has used filters or optional filters, the filters criterion will rank records according to a filtering score. All filters default to a score of 1. Records that match a single filter will have a score of 1 and will therefore score higher than records that don’t match any filter (1 > 0). Equally, records that match more than one filter will score higher than records with less matches - because Algolia counts each match.
For purposes of tie-breaking, all records with the same score are ranked the same, and so the ranking formula will drop to the next criterion to break the tie. You can adjust the scoring in 2 significant ways:
- With filter scoring, you can use variable scores, scoring some filters higher than 1. By setting a filter with a score = 2, or score=3, you can favor that filter over others.
- With sumOrFiltersScores, you can accumulate the scores of disjunctive (OR) matches to come up with a total score, ranking records higher than records with a lesser total score.
The Filters criterion can be quite powerful in defining relevance, as seen in the promoting results example.
Proximity#
For a query that contains two or more words, Proximity calculates how physically near those words are to each other in the matching record. This criterion will rank higher the objects that have the words closer to each other.
For example, George Clooney is a better proximity match than George Timothy Clooney.
Attribute#
The Attribute criterion only considers attributes you have placed in the searchableAttributes
(also referred to as AttributesToIndex). Additionally, attributes at the top of the searchableAttributes list rank higher than lower ones.
There is also an importance to the order of the matches within the attribute itself. By default, records whose matched words are closer to the beginning of a given attribute will be ranked higher. For example, words in position 2 of an attribute are ranked higher than words in position 5. Otherwise, the position of the word isn’t taken into account.
Exact#
Records with words that match query terms exactly are ranked higher. The more matching words in a record’s attribute, the higher a record is ranked. By default, an exact match occurs when a full word in a query is matched without typos to a word in an attribute. An inexact match is one that has typos or only matches on a prefix.
Additionally, synonym matching and plural/singular matching are considered exact. Thus, a word is considered an exact match if its synonym matches a query exactly.
Single-word queries are only exact if they match on a single-word attribute.
You can configure the settings for the exact criterion to change the default behavior.
Custom#
This criterion takes into account the settings that you have selected using Custom Ranking.
If you have multiple attributes in your Custom Ranking, the behavior will be the same as for the rest of the Ranking Formula: a criterion is only looked to refine the ranking when there is a tie on all the previous criteria.
For example, if you have the following Custom Ranking:
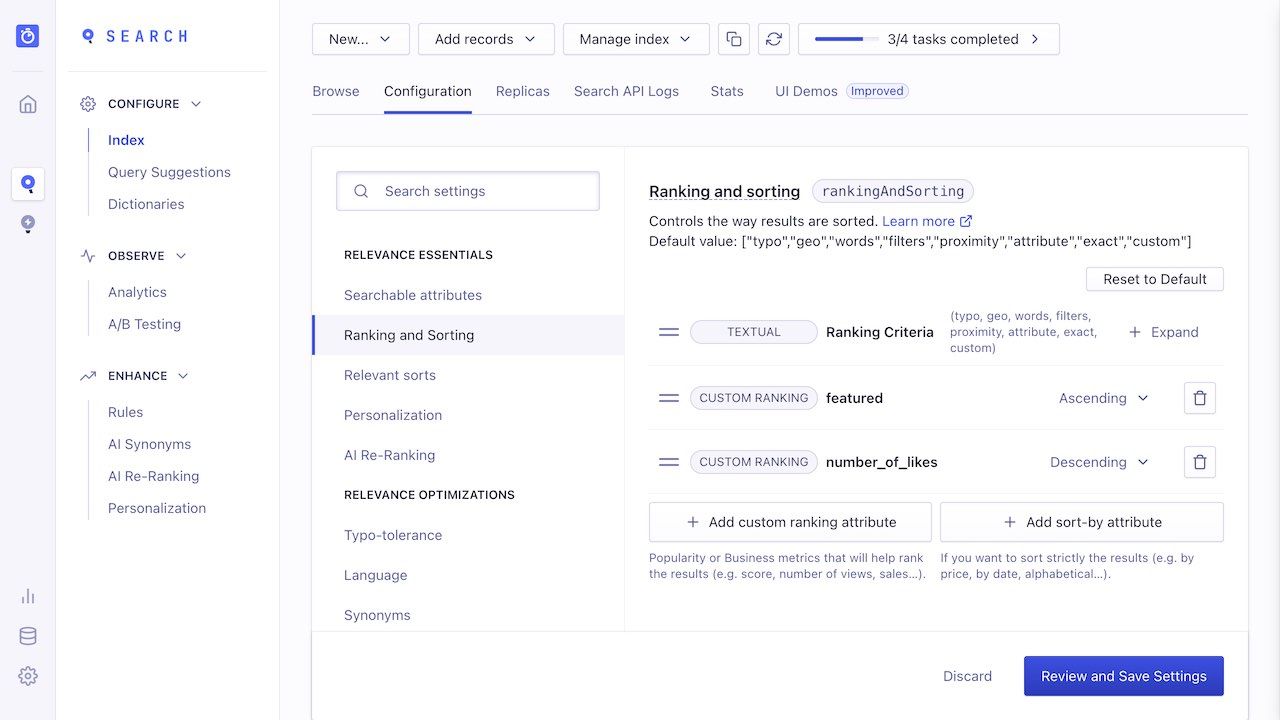
with featured being either true or false, and number_of_likes being a numerical value, then the tie-breaker for objects with the same ranking after the 6 first criteria will be as follows:
- Featured objects, ranked from the most to the least liked
- Not featured objects, ranked from the most to the least liked
Criteria combinations# A
For the most part, the ranking formula follows the preceding record scoring process. However, some combinations of criteria can score differently depending on their relative position to each other. One such combination is attribute and proximity.
Attribute and proximity#
When proximity appears before attribute in the ranking, the calculation of the attribute ranking will be different than if proximity had appeared after attribute. This is called best-matched attribute. For tie-breaking purposes, the ranking formula looks to the best-matched attribute.
Computing the “best-matched attribute”
As you will see below, Algolia uses two computation methods: closest in proximity and best position. The closest in proximity method refers to scoring based on how close two or more query terms are to each other. Best position considers words near the beginning of an attribute better than those towards the end.
As seen in the ordering of the eight criteria, the default ranking formula puts proximity before attribute, which has a subtle but important effect on computing the best-matched attribute: attributes whose matched terms are closest in proximity to each other will be ranked highest.
On the other hand, if you change the default by putting proximity after attribute, or removing proximity altogether, the best-matched attributes will be those whose matched terms are in the best position.
Foe example, imagine an index with two searchable attributes - profession, full-name - and the following two records:
1
2
3
4
5
6
7
8
9
10
11
12
[
{
"profession": "Singer and comedian",
"full-name": "Jerry Lewis",
"objectID": "3"
},
{
"profession": "Born a singer",
"full-name": "Jerry Singer",
"objectID": "1"
}
]
Specifically, consider the search query “Jerry Singer”. The default ranking formula order is proximity before attribute. In this case, the object that contains the two words “jerry” and “singer” in closest proximity is ranked higher (regardless of attribute order). For the two example objects:
- the record with an objectID of 1 has the query words side by side in the full-name attribute,
- while the record with an objectID of 3 has the query words in different attributes. Because the former has a better proximity, it’s ranked first.
On the other hand, if you put proximity after attribute, the ranking will now be based on the “best position” of the matched terms within the searchable attributes (profession, full-name). Consequently, with the query “jerry singer”, the term “singer” shows up in profession before full-name:
Subtle. It’s recommended that you keep the proximity criterion before the attribute criterion. Proximity usually leads to a better identification of the best-matched attribute.
