Quickstart for the Algolia Crawler
This page uses an example to teach you how to make and use a crawler. You’ll learn how to crawl the Algolia blog at algolia.com/blog and index the content in an Algolia index named crawler_default_index_name.
Initialization# A
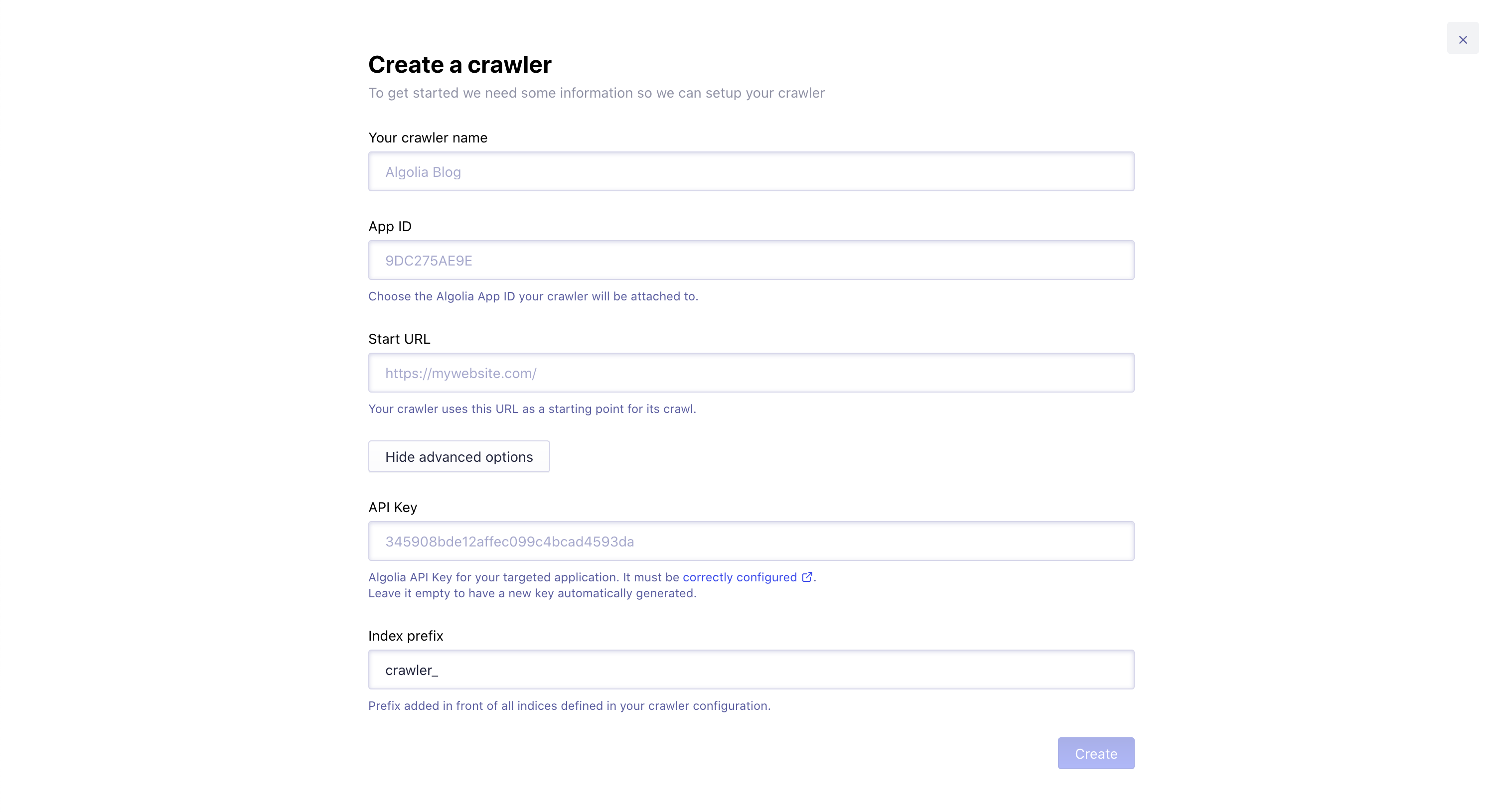
Create a new crawler on the Crawler dashboard by clicking on the Create new crawler button.
Fill in the required fields with the following information:
- Crawler Name: Algolia Blog
- App ID: the Algolia application you want to target
- Start URL:
https://www.algolia.com/blog
Advanced options#
- API Key: by default, one is generated for your crawler, but you can use an existing one from your Algolia dashboard
- Algolia Index Prefix:
crawler_
Now that your crawler is created, you can edit and view its configuration. You can do this from the Editor tab of the Admin.
Default Configuration File# A
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
new Crawler({
appId: "YOUR_APP_ID",
apiKey: "YOUR_API_KEY",
indexPrefix: "crawler_",
rateLimit: 8,
maxUrls: 500,
startUrls: ["https://www.algolia.com/blog"],
ignoreQueryParams: ["utm_medium", "utm_source", "utm_campaign", "utm_term"],
actions: [
{
indexName: "default_index_name",
pathsToMatch: ["https://www.algolia.com/blog/**"],
recordExtractor: ({ url, $, contentLength, fileType }) => {
console.log(`Crawling "${url.href}"`);
return [
{
// URL
url: url.href,
hostname: url.hostname,
path: url.pathname,
depth: url.pathname.split("/").length - 1,
// Metadata
contentLength,
fileType,
title: $("head > title").text(),
keywords: $("meta[name=keywords]").attr("content"),
description: $("meta[name=description]").attr("content"),
type: $('meta[property="og:type"]').attr("content"),
image: $('meta[property="og:image"]').attr("content"),
// Content
headers: $("h1,h2")
.map((i, e) => $(e).text())
.get()
}
]
}
}
],
initialIndexSettings: {
default_index_name: {
searchableAttributes: [
"unordered(keywords)",
"unordered(title)",
"unordered(description)",
"unordered(headers)",
"url"
],
customRanking: ["asc(depth)"],
attributesForFaceting: ["fileType", "type"]
}
}
});
The default crawler configuration works on the Algolia Blog. If you want, you can start crawling right away.
To offer a better understanding of the default crawler object, we’ll first provide a quick high level overview of its components.
Each crawler has a configuration file. The configuration file starts by defining a crawler object, which is made of top level parameters, actions, and index settings.
Top level parameters#
The following parameters apply to all your actions:
You can find your API keys on the API key tab of your Algolia dashboard
indexPrefix: the prefix added to the Algolia indices your crawler generates.rateLimit: the number of concurrent tasks (per second) that can run for this crawler.maxUrls: the maximum number of URLs your crawler will crawl.startUrls: the URLs that your Crawler starts on.ignoreQueryParams: the parameters added to URLs as the crawl progresses that you want to ignore (you don’t have to worry about this parameter for now).
Actions#
A crawler can have any number of actions. An action indicates a subset of your targeted URLs that you want to extract records from in a specific way. For example, suppose you want to crawl a site which contains a blog, a homepage, and documentation. You likely need a unique recordExtractor for each section and may want to store their content in different indices: to accomplish this, you can use actions.
Actions include:
- an
indexName, which defines the Algolia index extracted records will go to, - and
pathsToMatchwhich defines the pattern(s) URLs must match to be processed by the action.
Actions also contain a recordExtractor. A recordExtractor is a function that defines how content from an action’s webpages should be extracted and formatted into Algolia records. For more details on the recordExtractor, please read our extraction guide.
Index settings#
The initialIndexSettings part of your crawler defines the default settings of your crawler generated Algolia indices.
These settings are only applied the first time you run your crawler. For all subsequent crawls, initialIndexSettings is ignored.
Start crawling# A
To start your crawler, go to the Overview tab and click on the Start crawling button. After a couple of minutes, the crawl should finish.
To better understand your crawler, let’s take a look at what happened when you clicked the Start crawling button.
Link extraction# A
Clicking on Start crawling launches a crawl that starts from the URLs you provide in the startUrls, sitemaps, and extraUrls parameters of your crawler object. startUrls defaults to the homepage you provided when you created your crawler, but you can add custom starting points by editing your crawler’s configuration.
1
startUrls: ["https://www.algolia.com/blog/"],
Your crawler fetches the start page(s) and extracts every link they contain. However, it doesn’t follow every link: otherwise you could end up inadvertently crawling a huge chunk of the web.
For example, if your site has a link to a popular Wikipedia page, every link on that Wikipedia page would be crawled, and all the links on those pages too, and so on. As you can imagine, this can quickly become unmanageable. One of the critical ways you can restrict which links your crawler follows is with the pathsToMatch field of your crawler object.
The scope of your crawl is defined through the pathsToMatch field. Only links that match a path found in pathsToMatch are crawled. This field defaults to paths starting with the same URL as your homepage.
1
pathsToMatch: ["https://www.algolia.com/blog/**"],
Content extraction# A
The following recordExtractor is applied to each page that matches a path in pathsToMatch:
1
2
3
recordExtractor: ({ url, $, contentLength, fileType }) => {
return [{ url: url.href, title: $('head > title').text() }];
}
This recordExtractor creates an array of records per crawled page and adds those records to the index you defined in your actions indexName field (prefixed by the value of indexPrefix).
You can verify the process in your Algolia dashboard.
You should find an index with the indexName you defined, prefixed by the indexPrefix. For our example, the index would be called crawler_default_index_name.
For a complete overview of recordExtractors, read our extractors guide.
Exclusions# A
Now, let’s take a look at the Monitoring tab of your Crawler dashboard. On this page, you may see that the crawler has ignored a number of pages. This is valuable information: if you can identify a pattern to the ignored pages, you can tell the crawler to exclude these pages on future reindexes.
Excluding is not the same as ignoring. An excluded page is not crawled. An ignored page is crawled (or a crawl attempt is made) but nothing is extracted.
Excluding pages has two main advantages:
- It lowers the resource usage of your crawler on our infrastructure.
- It speeds up your crawling by only fetching and processing meaningful URLs.
In our blog example, we don’t have any specific ignored URLs. However, we have typical URLs that we might want to exclude, such as password-protected pages of the website for example.
These pages would appear as HTTP Unauthorized (401) or HTTP Forbidden (403) entries in the Monitoring section.
When you have identified a pattern, you can exclude these URLs:
- Go to the Settings tab, and scroll down to the Exclusions section.
- Click the Add an Exclusion button, enter your pattern, for example,
https://www.algolia.com/blog/private/**, and click Save. - At the bottom of your configuration file, you should find the following:
Copy
1
exclusionPatterns: ['https://www.algolia.com/blog/private/**'],
- Go to the Overview tab and click the Restart crawling button.
- Once the crawl is finished, reopen the Monitoring tab to confirm that the
HTTP Unauthorized (401)errors are gone.
See the documentation for exclusionPatterns.
Advanced crawler configuration# A
That’s it for the quick introduction.
You can find the complete configuration reference on the Configuration API page.
Or checkout our Github Repository of sample crawler configuration files.
