Get Started Using the Crawler Admin
The Crawler Admin is an interface for accessing, debugging, testing, configuring, and using your crawlers.
Admin Layout# A
After logging into the Crawler Admin, you’ll arrive on the home page. From the home page, you can select one of your crawlers or create a new one.
If you select a crawler, you’ll be taken to the overview page for your selected crawler.
This new section has a sidebar, and a main content area. The main content area changes depending on the section you’ve selected from the sidebar.
The Sidebar Menu# A
The sidebar is the Admin’s main menu. With it, you can switch between eight tabs:
You can also use the sidebar to:
- return to the admin homepage (where you can select a different crawler or make a new crawler),
- go to the crawler docs,
- send us feedback,
- ask for support,
- access your account settings.
Overview# A
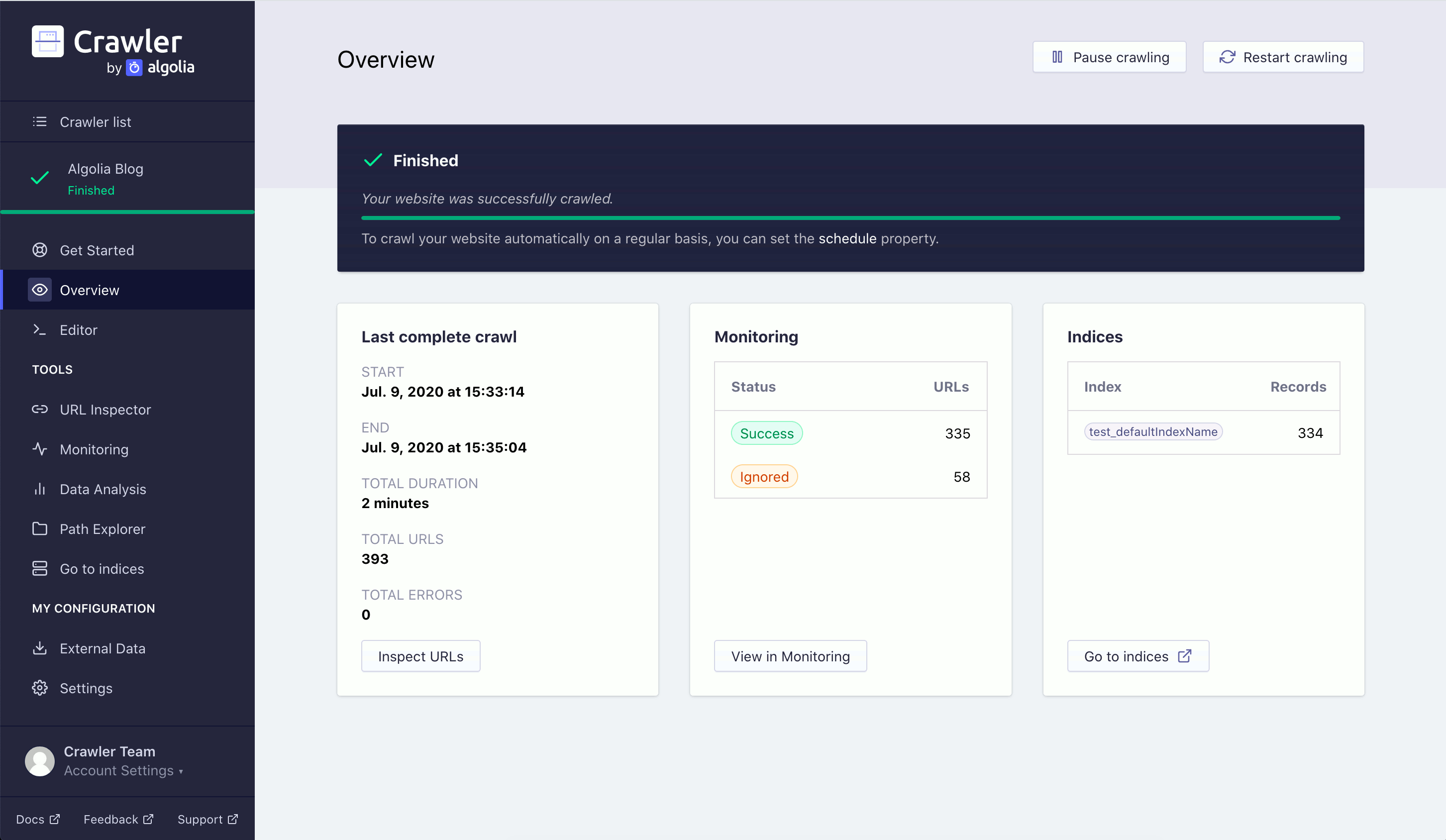
At the top of the Overview tab you’ll see a Restart crawling button. Click this button to start a crawl. There are four more sections on the overview page:
- A progress bar.
- A high level summary of your previous crawl.
- A high level monitoring overview of your previous crawl.
- A list of your crawler indices.
Editor# A
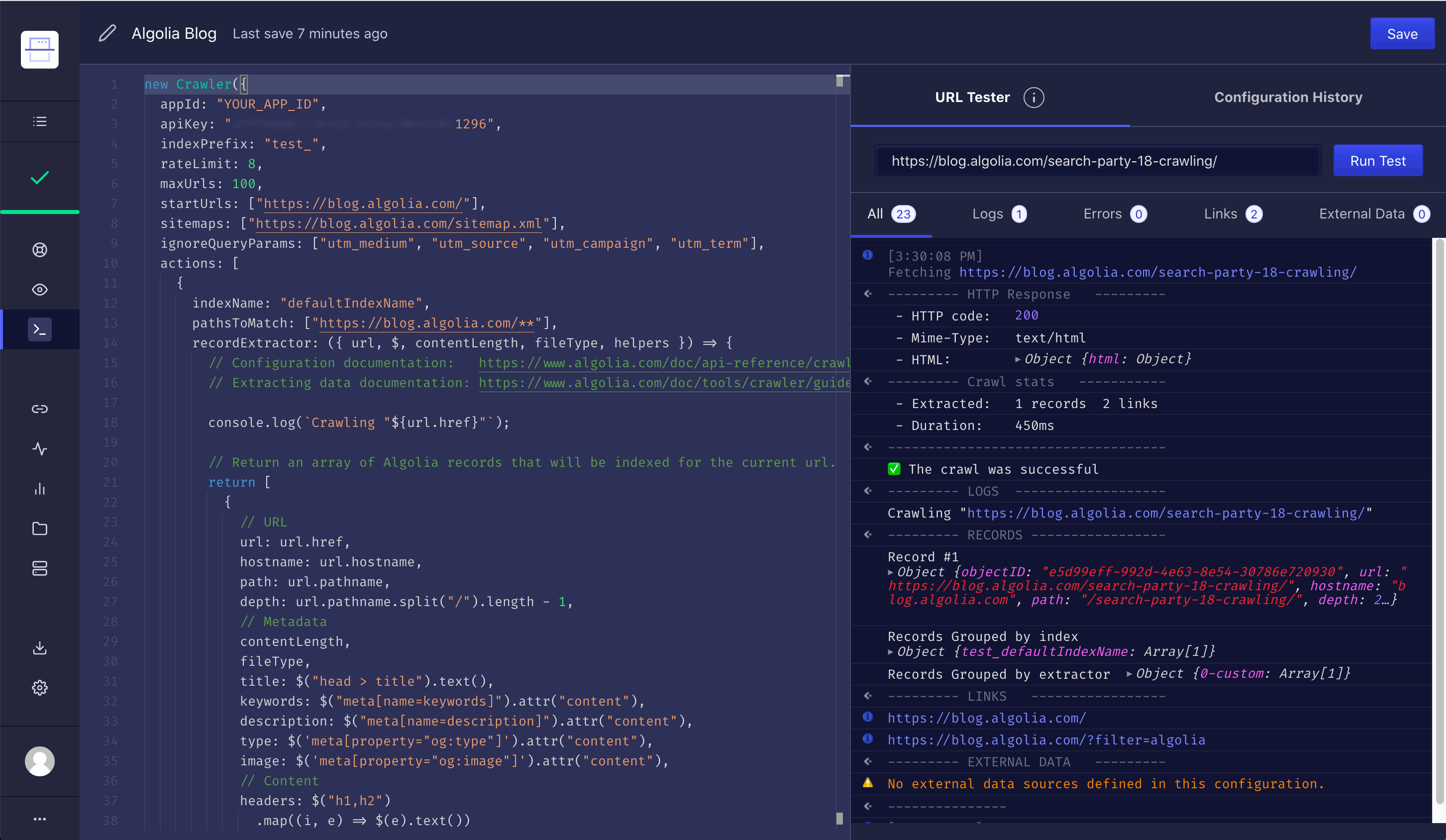
The Editor tab takes you to an in-browser code editor where you can directly edit your crawler’s configuration.
This page also features a Test URL input field. Enter a URL into the test field and click Run Test to get a detailed overview of your crawler’s response to the specified page. This is a good way to ensure that you have properly configured your crawler.
URL Inspector# A
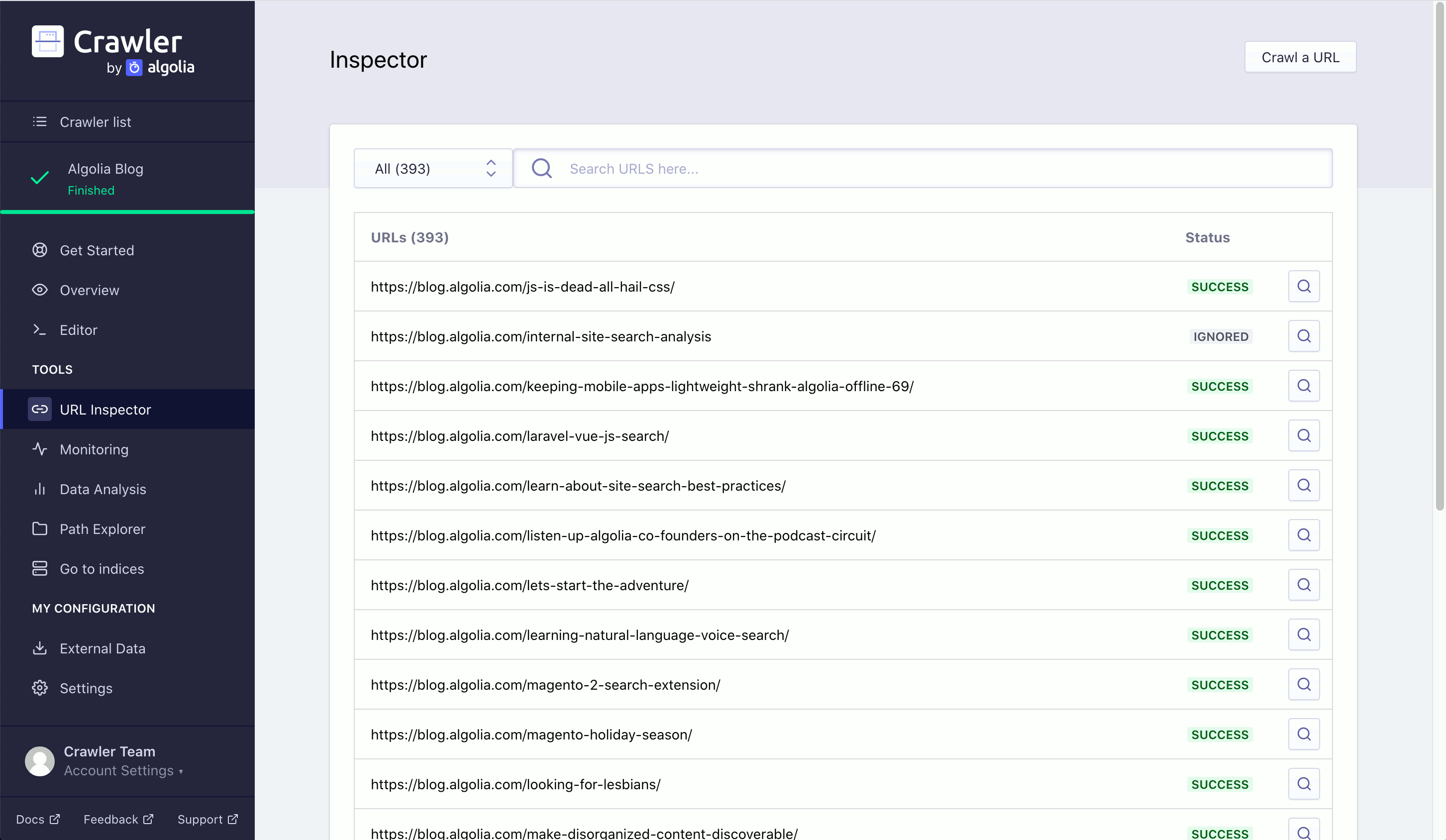
In the URL Inspector you can search through all the URLs you’ve crawled. On the main page, you can see whether a URL was crawled, ignored, or failed. You can get more information on the crawling result of a URL by clicking on the magnifying glass icon: this will show you metadata and extraction details for the page.
Monitoring# A
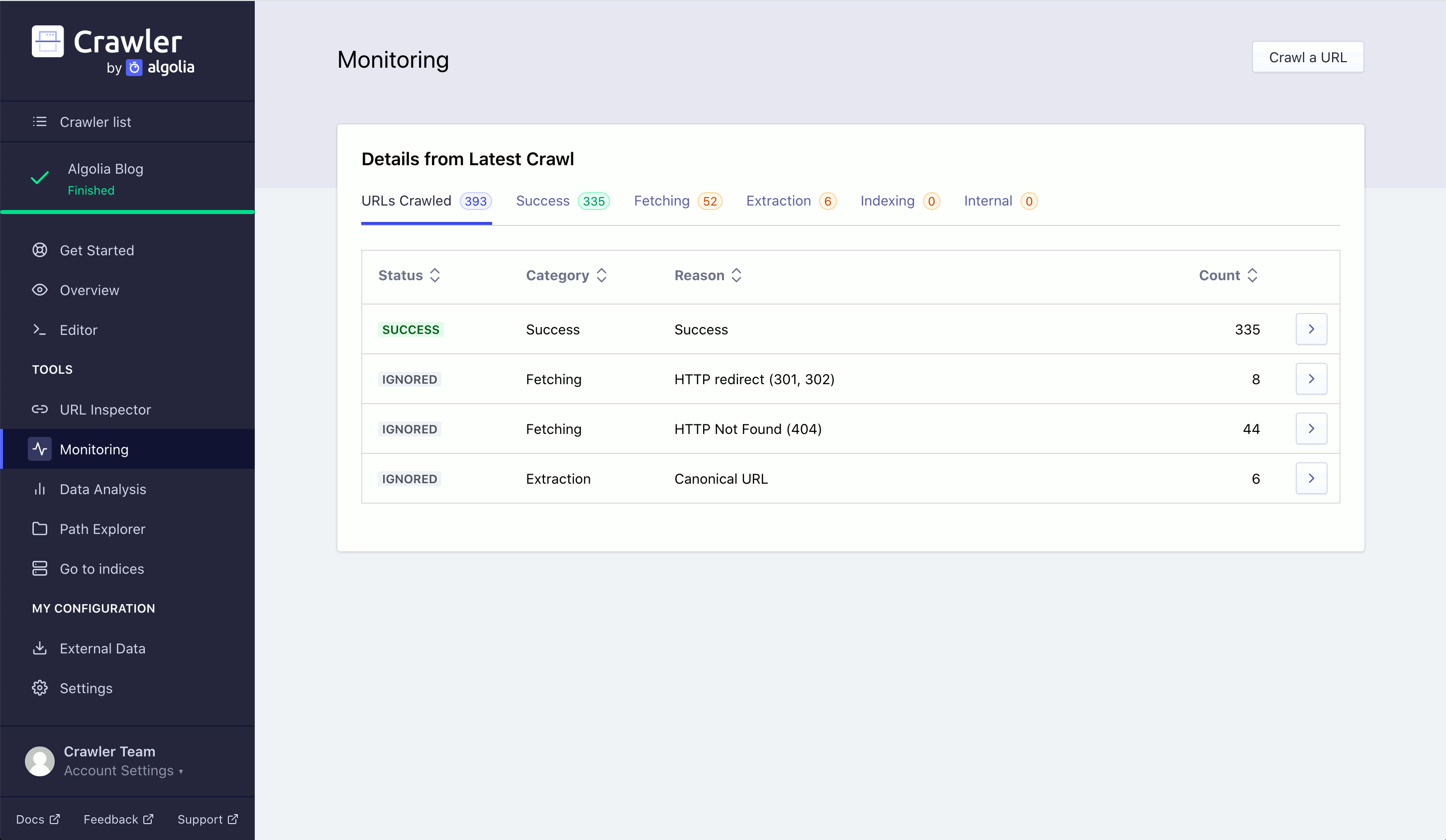
In the Monitoring tab, you can sort your crawled URLs based on the result of their crawl. A crawled URL has one of three statuses: success, ignored, failed. Each URL also has one of five categories:
- success
- fetch error
- extraction error
- indexing error
- internal error
You can filter your crawled URLs on these categories, using the tabs beneath the Details from Latest Crawl header. Each URL also provides a reason, which explains why the error happened.
You can view all URLs with a particular reason by clicking on any value in the reason column. You can also click on the number in the pages affected column to view a list of the affected pages’ URLs for any specific row.
Data Analysis# A
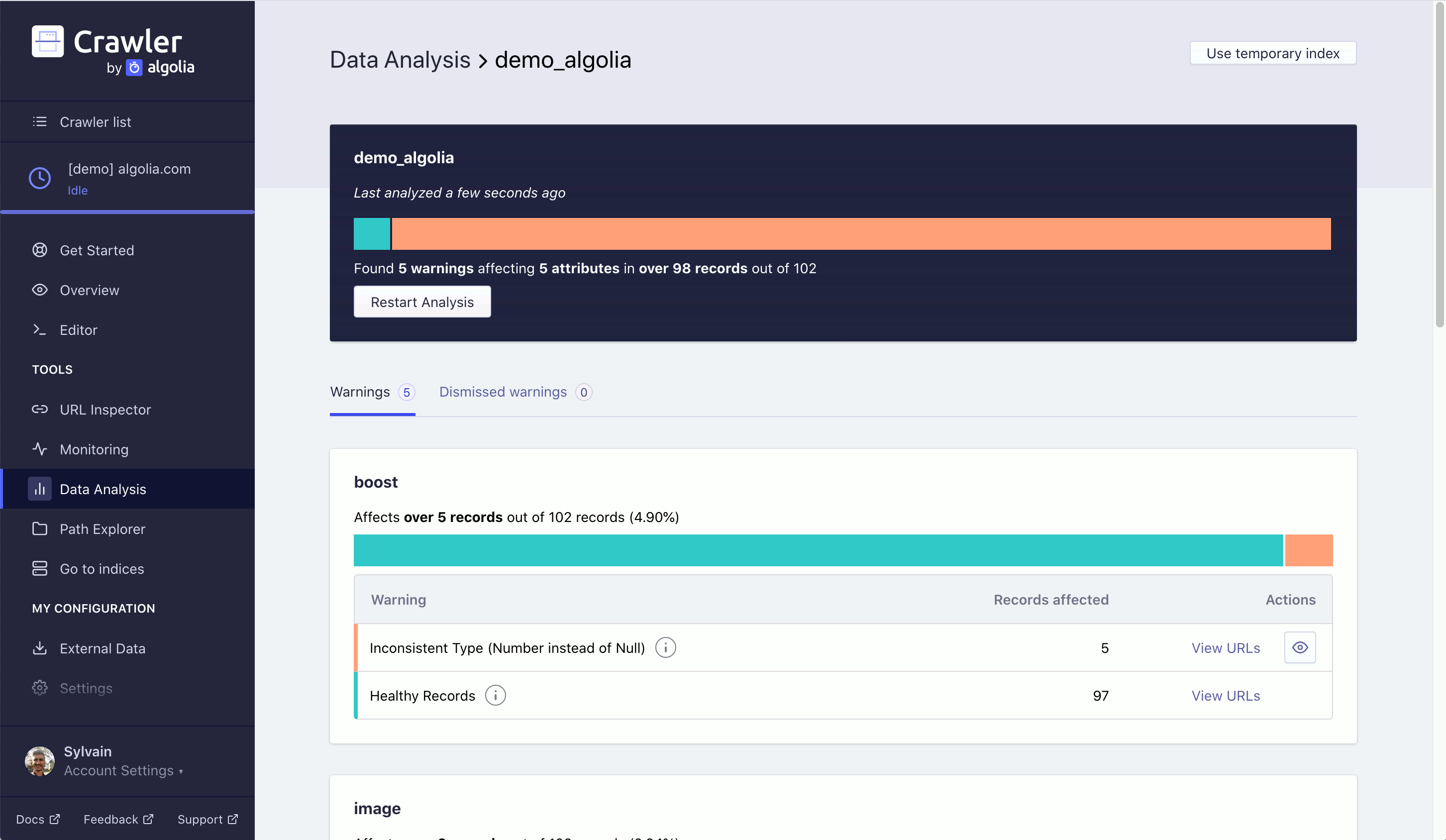
In the Data Analysis tab, you can test the quality of your crawler generated index. Clicking on Analyze Index for one of your crawler generated indices gives you information on the completeness of your records. It lets you know if any of the records you generated are missing any attribute(s). The analysis will also tell you the associated URLs of records that are missing attributes.
This can be a very effective way of debugging your indices.
Path Explorer# A
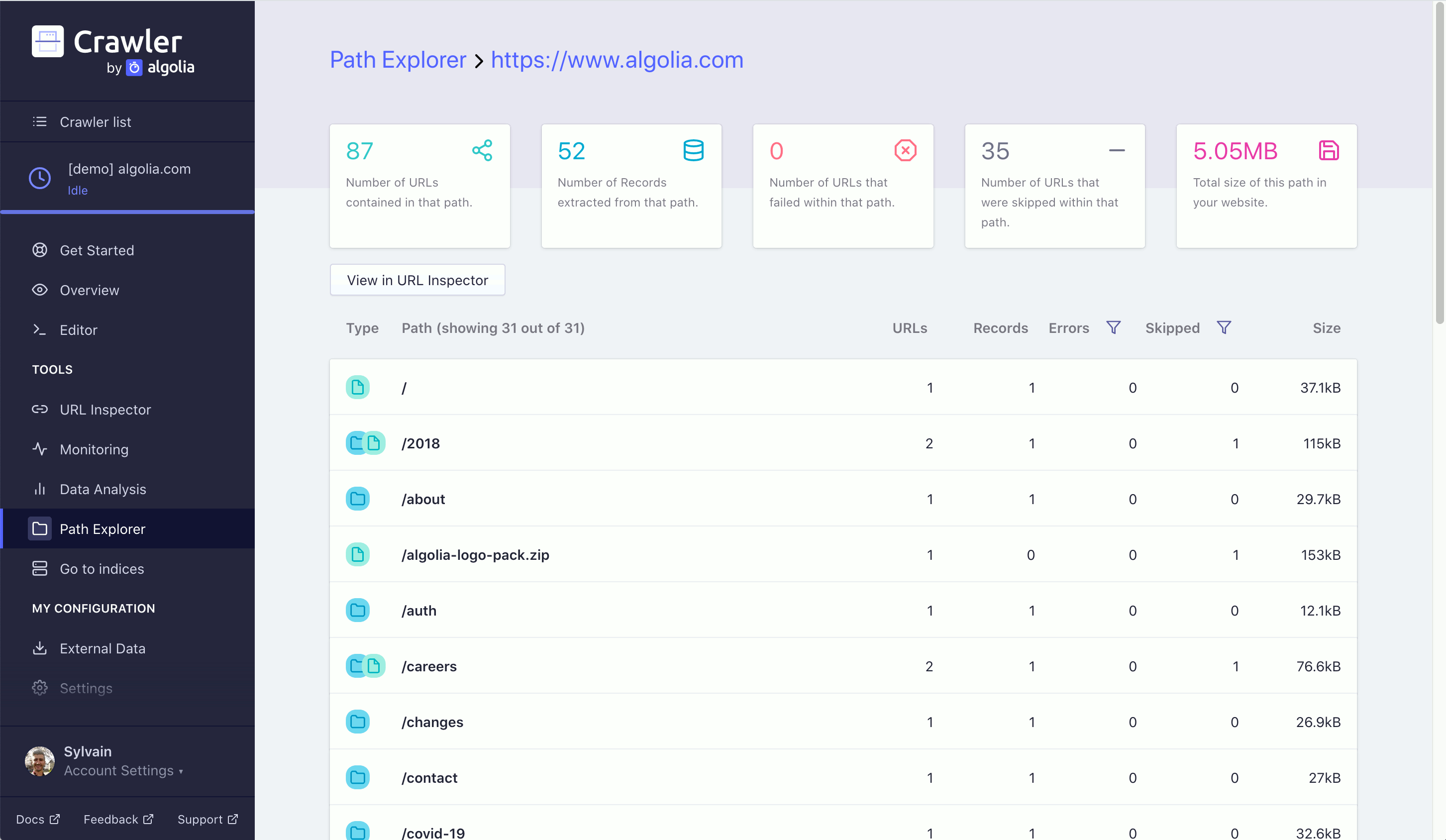
In the Path Explorer tab, your crawled URLs are organized in a directory. The root folders are defined by your startUrls. The URL path of your current folder is shown in the Path Explorer header. Folders are represented by blue circles with folder icons: clicking on them takes you to a sub directories and appends the folder’s name to your URL path. Files are represented by green circles with file icons: they take you to the URL inspector for the current path with the clicked file’s name appended.
A file that is just a / is the page associated with the current Path Explorer URL.
External Data# A
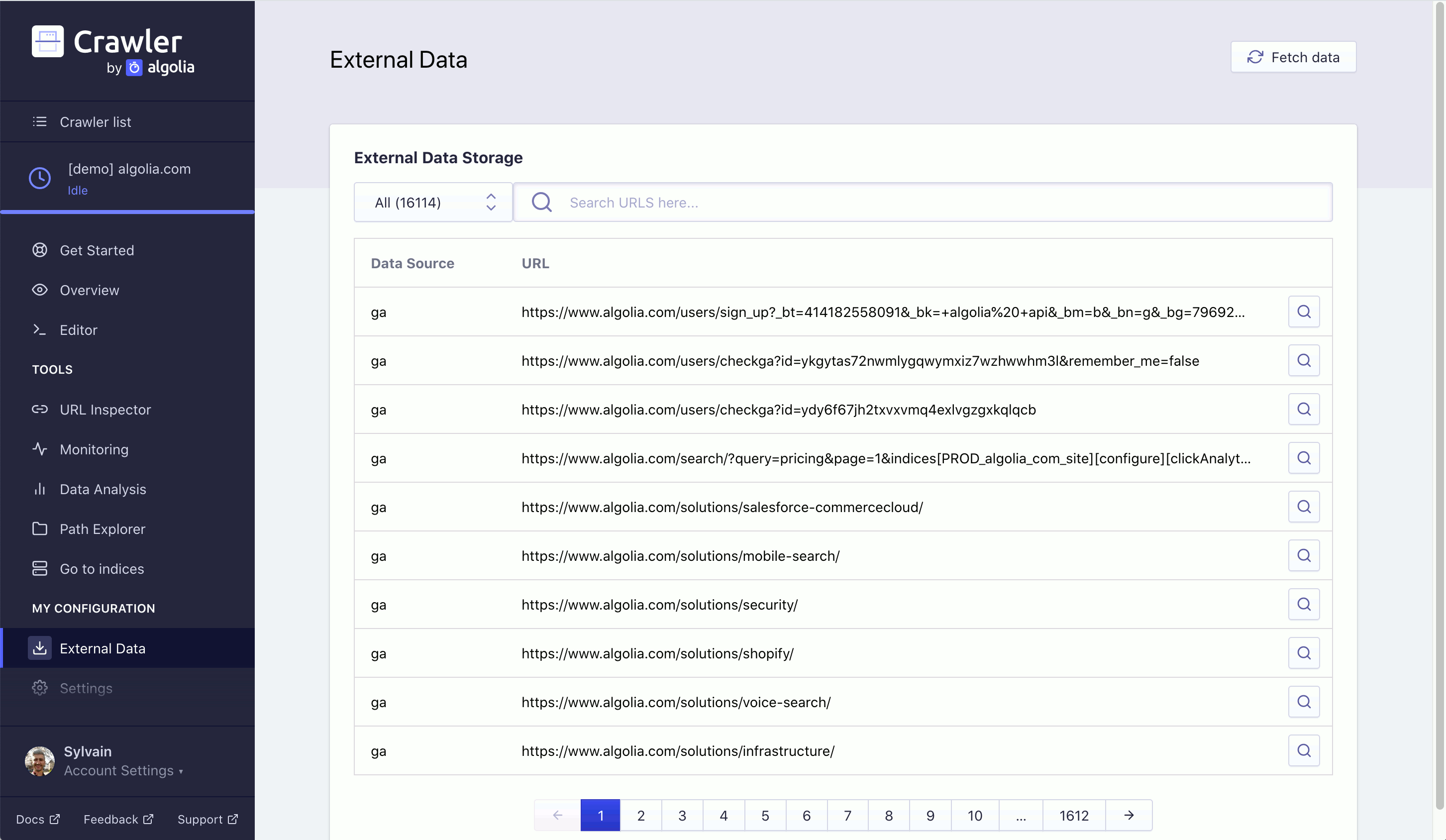
In the External Data tab you can view the external data passed to each of your URLs. You can search through all your crawled URLs. Clicking on the magnifying glass icon for a specific URL takes you to a page with its associated external data.
Settings# A
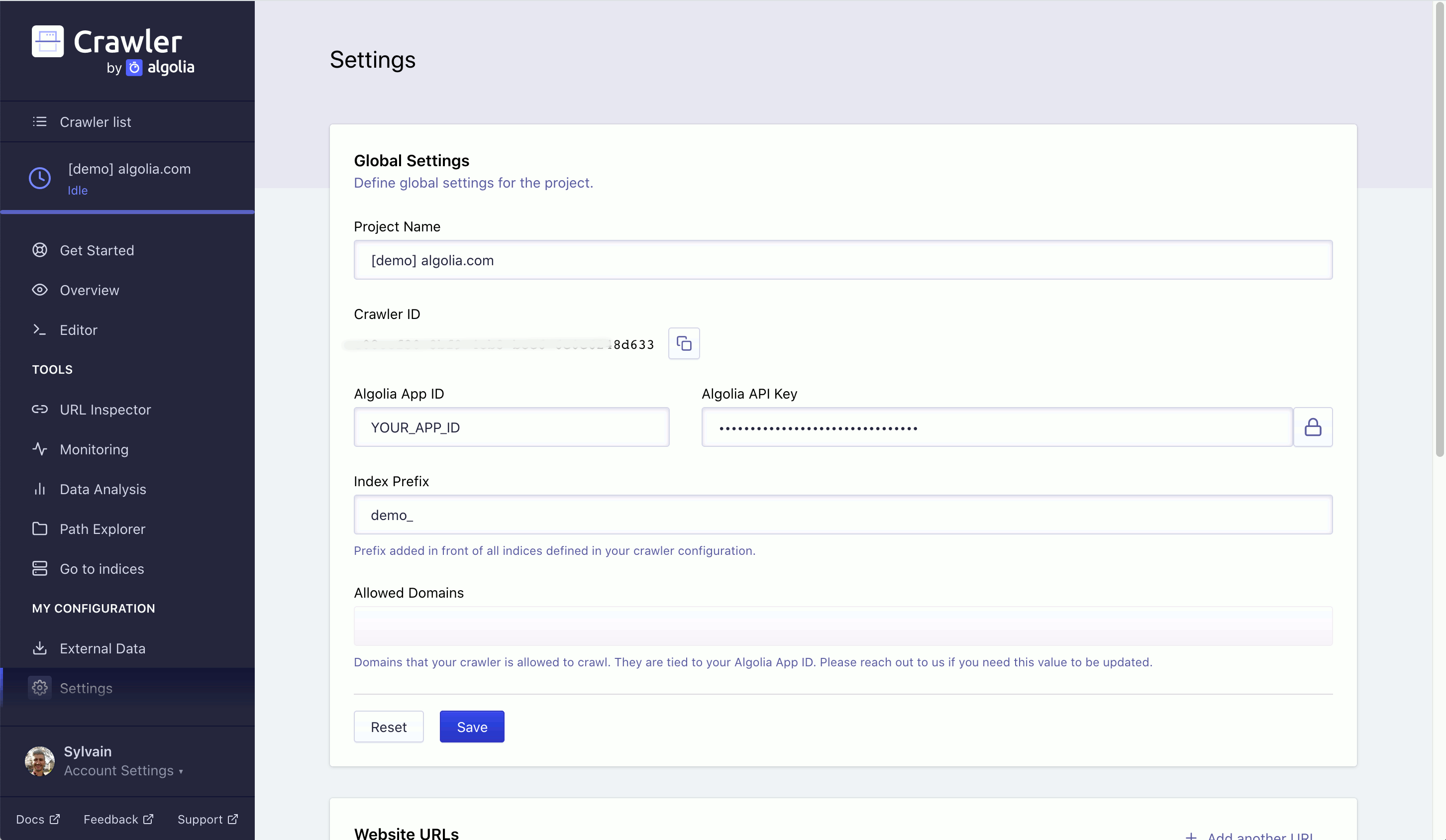
In the Settings tab, you can specify your crawler’s settings. You can edit:
- Global Settings: your project’s name, Algolia App ID, Algolia API key, and your
indexPrefix.
These should have been set when you created your crawler. Under Global Settings you can also see your Crawler ID.
- Website Settings: set your
startUrls(creating you crawler should set a default value, but you can add more start points). - Exclusions: set your
exclusionPatterns(which URL paths you want your crawler to ignore).
You can also delete your crawler by pressing the Delete my crawler button.
