Crawler REST API
Basics# A
Our Crawler is based on a REST API.
With it, you can perform a number of operations, including:
- Creating and updating your crawlers in batches.
- Running automated tests.
- Customizing your monitoring.
The API endpoints#
Currently, the API has 11 available endpoints. These endpoints let you create, update, run, pause, test, and get statistics on your crawlers.
Our Crawler REST API docs detail each endpoint. You can test endpoints from the API’s base URL.
The API is exposed at https://crawler.algolia.com/api/1/. Attach this path to your desired endpoint to make your API calls.
Authentication#
All endpoints are protected by a Basic Authentication scheme that requires a Crawler User ID and a dedicated Crawler API key.
To see your user ID and API key, go to the Crawler Admin, click on your name, and then go to the settings page. Your ID and key are at the top of this page.
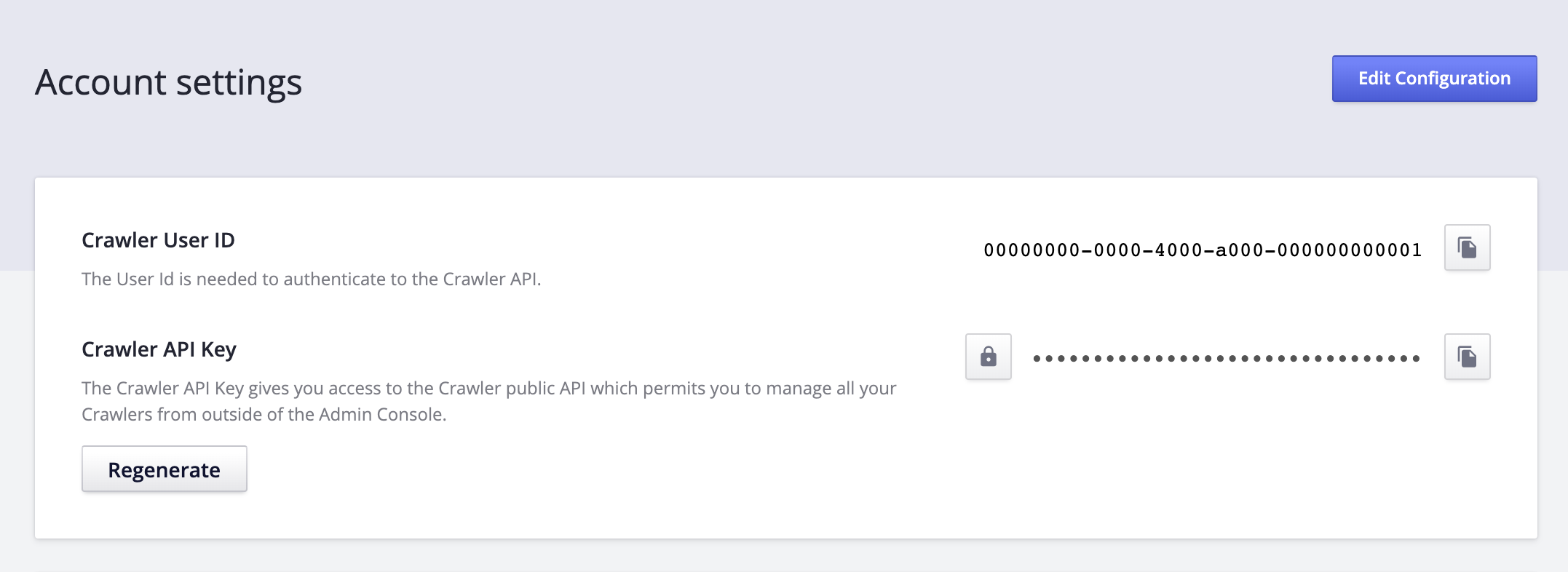
Basic Authentication is a login/password authentication scheme, the user ID is the username and the API key is the password.
$
curl -H "Content-Type: application/json" --user {user-id}:{api-key} "https://crawler.algolia.com/api/1/"
Crawler configuration format#
While your crawler configuration file is in JavaScript, our API works with JSON. We do this to make the API easier to use, but it has a drawback. The JSON format does not support JavaScript functions.
If you plan to use our API for configuration, you will likely need to pass JavaScript functions. As a result, we have introduced an intermediary representation for JavaScript functions in JSON. Below is an example of:
- A JavaScript function from a Crawler configuration.
- The intermediary JSON representation of that function.
1. JavaScript function#
1
recordExtractor: ({ url }) => { return [{ objectID: url.pathname }]; }
2. JSON intermediary#
1
2
3
4
"recordExtractor": {
"__type": "function",
"source": "({ url }) => { return [{ objectID: url.pathname }]; }"
}
Getting started# A
Now that you have your Crawler API key and user ID, you need to get your Crawler ID. To do this, select your crawler from the Crawler Admin, and click on the Settings tab.
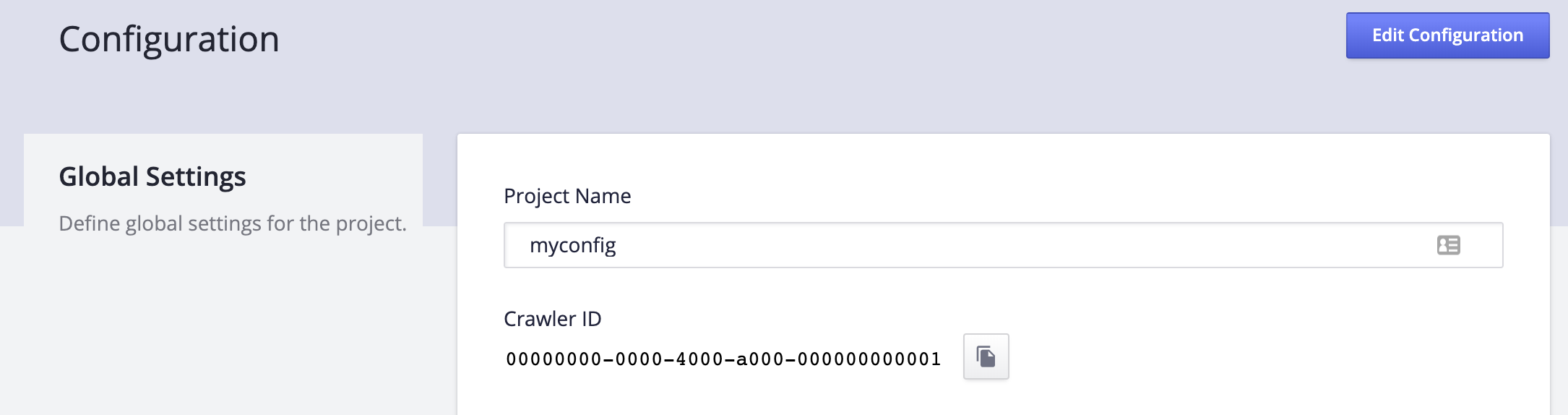
You can now make your first API call:
$
curl -H "Content-Type: application/json" --user {user-id}:{api-key} "https://crawler.algolia.com/api/1/crawlers/{crawler-id}"
Walkthrough of a use case# A
We’ll now explore the following use case: creating, updating, and checking the configurations of three similar crawlers in parallel.
Before running the provided examples, set the following environment variables:
CRAWLER_USER_ID(used to authenticate each API call)CRAWLER_API_KEY(used to authenticate each API call)CRAWLER_API_BASE_URL(if possible, on a test environment):https://crawler.algolia.com/api/1/ALGOLIA_APP_ID(used in the test configuration)ALGOLIA_API_KEY(used in the test configuration)
You can find your Algolia app ID and your Algolia API key on the API key tab of your Algolia dashboard
Generate your Authentication Token#
In Node:#
1
2
3
const BASE64_BASIC_AUTH = `Basic ${Buffer.from(
`${process.env.CRAWLER_USER_ID}:${process.env.CRAWLER_API_KEY}`
).toString('base64')}`;
In your browser:#
1
2
3
const BASE64_BASIC_AUTH = `Basic ${btoa(
`${CRAWLER_USER_ID}:${CRAWLER_API_KEY}`
)}`;
Create your crawlers#
To create a crawler, call the /crawlers endpoint with a name and a configuration as parameters. To create three crawlers, do the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
async function createConfig(name, indexName) {
console.log(`Creating config ${name}`);
const res = await fetch(`${process.env.CRAWLER_API_BASE_URL}/crawlers`, {
method: 'POST',
headers: {
Authorization: BASE64_BASIC_AUTH,
'Content-Type': 'application/json',
},
// getConfig() will generate a simple test configuration with a few parametrized entries
body: JSON.stringify({ name, config: getConfig(name, indexName) }),
});
const jsonResponse = await res.json();
// Each success response will look like: { id: '2739fdf6-8a09-4f5b-a022-762284853d73' }
// The id is the Crawler's id, the one that you can see in the URL of the Crawler Admin Console
// Now, extract this Crawler's id from the response and store it for later
}
Control your crawlers#
To control your crawlers, the API provides crawl, run, and pause methods. In the following example, we’ll start a crawl.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
async function reindex(crawlerId) {
console.log(`Triggering reindex on ${crawlerId}`);
const res = await fetch(
`${process.env.CRAWLER_API_BASE_URL}/crawlers/${crawlerId}/reindex`,
{
method: 'POST',
headers: {
Authorization: BASE64_BASIC_AUTH,
'Content-Type': 'application/json',
},
}
);
const jsonResponse = await res.json();
// Each success response will look like: { taskId: '18bf6357-fbad-42b2-9a0f-d685e25a24f9' }
// Use the '/crawlers/{id}/tasks/{taskId}' endpoint to get the status of the task
}
The response you get from the Crawler contains a taskId. This ID is important because there can be race-conditions in your calls to the Crawler REST API.
For example, if you update a crawler’s configuration while a crawl is running, your crawler needs to execute the configuration task asynchronously: it must wait for the crawl to end.
To know if your task has been processed, ping the /crawlers/{id}/tasks/{taskId} endpoint.
If the task is pending, the response will be { "pending": true }. If the pending field is false,
the task has been processed.
Monitor your crawlers#
Now that your crawlers are running, you can start getting statistics on their performances. You can use these statistics to monitor your crawlers and trigger custom alerts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
async function getURLStats(crawlerId) {
const res = await fetch(
`${process.env.CRAWLER_API_BASE_URL}/crawlers/${crawlerId}/stats/urls`,
{
headers: {
Authorization: BASE64_BASIC_AUTH,
'Content-Type': 'application/json',
},
}
);
const jsonResponse = await res.json();
console.log(jsonResponse);
/*
{
"count": 215,
"data": [
{
"reason": "success",
"status": "DONE",
"category": "success",
"readable": "Success",
"count": 206
},
{
"reason": "forbidden_by_robotstxt",
"status": "SKIPPED",
"category": "fetch",
"readable": "Forbidden by robots.txt",
"count": 1
},
{
"reason": "http_redirect_invalid",
"status": "SKIPPED",
"category": "fetch",
"readable": "HTTP redirect (301, 302) - Not followed",
"count": 2
},
...
}
*/
}
Test your crawlers#
With the API, you can also test specific configurations on specific URLs.
Tests return useful information such as the Algolia records generated by your configuration’s recordExtractors.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
async function testUrl(crawlerId, urlToTest) {
const res = await fetch(
`${process.env.CRAWLER_API_BASE_URL}/crawlers/${crawlerId}/test`,
{
method: 'POST',
headers: {
Authorization: BASE64_BASIC_AUTH,
'Content-Type': 'application/json',
},
body: JSON.stringify({
url: configInfo.testUrl,
}),
}
);
const jsonResponse = await res.json();
console.log(jsonResponse.records[0].records);
/*
[ { objectID: '5656787',
title:
'Nintendo - Nintendo 2DS™ - Electric Blue 2 with Mario Kart™ 7 - Electric Blue 2',
img: 'https://cdn-demo.algolia.com/bestbuy-0118/5656787_sb.jpg',
rating: 4,
onsale: false } ]
*/
}
You can also pass parts of a configuration in the body of your request. These parts override your current configuration for the duration of the test.
Update your crawlers#
After running your crawler, you may want to update its configuration to make it more effective. To do this, you can pass either a whole crawler object or only the parts that you want to update. In the example below, we pass parts of a crawler object.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
const partialConfig = {
ignoreQueryParams: ['utm_medium', 'utm_source', 'utm_campaign', 'utm_term'],
schedule: "every 1 day",
};
// ...
async function updateConfig(crawlerId, partialConfig) {
console.log(`Updating config of crawler ${crawlerId}`);
const res = await fetch(
`${process.env.CRAWLER_API_BASE_URL}/crawlers/${crawlerId}/config`,
{
method: 'PATCH',
headers: {
Authorization: BASE64_BASIC_AUTH,
'Content-Type': 'application/json',
},
body: JSON.stringify(partialConfig),
}
);
const jsonResponse = await res.json(); // { taskId: 'some_task_id' }
}
Internally, the merge is done in the following way:
1
2
3
4
const updatedConfig = {
...currentConfig,
...partialConfig
};
Unblock your crawlers#
If you have multiple crawlers blocked and want to unblock them all at once, you can combine API calls to do so. You can save the example script below and execute it by running the following command:
1
CRAWLER_USER_ID=${CRAWLER_USER_ID} CRAWLER_API_KEY=${CRAWLER_API_KEY} node path/to/unblockAllCrawlersFileName.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
const fetch = require('node-fetch');
const CRAWLER_API_URL = 'https://crawler.algolia.com/api/1';
const CRAWLER_USER_ID = process.env.CRAWLER_USER_ID;
const CRAWLER_API_KEY = process.env.CRAWLER_API_KEY;
function getAuthorizationHeader() {
const credentials = `${CRAWLER_USER_ID}:${CRAWLER_API_KEY}`;
const encoded = Buffer.from(credentials).toString('base64');
return `Basic ${encoded}`;
}
async function unblockAllCrawlers() {
let currentPage = 1;
let nbFetchedCrawlers = 0;
let crawlers;
do {
// List your crawlers (id and name)
const res = await fetch(
`${CRAWLER_API_URL}/crawlers?page=${currentPage++}`,
{
headers: {
Authorization: getAuthorizationHeader(),
},
}
);
if (!res.ok) {
console.log(
`Error while fetching crawlers: ${res.statusText} (${res.status})`
);
console.log(await res.json());
return;
}
crawlers = await res.json();
nbFetchedCrawlers += crawlers.items.length;
for (const crawler of crawlers.items) {
// For each crawler, get its status
console.log(`Checking crawler ${crawler.id} (${crawler.name})`);
const response = await fetch(
`${CRAWLER_API_URL}/crawlers/${crawler.id}`,
{
headers: {
Authorization: getAuthorizationHeader(),
},
}
);
const crawlerDetails = await response.json();
if (crawlerDetails.blocked) {
console.log(` --> Blocking error: ${crawlerDetails.blockingError}`);
await fetch(
`${CRAWLER_API_URL}/crawlers/${crawler.id}/tasks/${crawlerDetails.blockingTaskId}/cancel`,
{
method: 'POST',
headers: {
Authorization: getAuthorizationHeader(),
},
}
);
console.log(` --> Crawler ${crawler.name} unblocked`);
}
}
} while (crawlers.total > nbFetchedCrawlers);
}
(async () => {
await unblockAllCrawlers();
})();
